
Developers have started asking AI which AI coding tool to buy. So we measured what the AI actually answers.
On July 3, 2026, we scanned 7 major AI coding and app-building tools — GitHub Copilot, Cursor, Devin, Replit, Bolt.new, Lovable, and Bubble — across 11 AI engines and search sources, using ~20 buying-intent prompts per tool. That’s 1,506 real engine answers, with every mention, citation, and source URL logged.
The headline: 4 of the 7 tools lost their own home turf. Each tool was scanned on prompts generated for its own positioning — and in four cases, a competitor still out-scored it on those prompts. Devin lost its agent-fleet prompts to Cursor. Bolt.new ranked 7th on its own scan.
And one engine — Gemini — mentioned brands in up to 85% of its answers while citing exactly zero sources in all 1,506 responses.
The experiment. 7 tools × ~20 prompts × 11 engines (ChatGPT, Gemini, Claude, Perplexity, Google AI Mode, Google AI Overview, Google Search, Bing Search, Bing Copilot, Tavily, Exa) = 1,506 answers, scanned July 3, 2026 with RankBits. For each answer we logged whether the brand was mentioned (named in the answer), cited (its site linked as a source), plus citation rank and every cited URL. Prompts were auto-generated per brand to match its positioning and vary in how competitive/popular they are, so each leaderboard row reflects a tool’s performance on its own prompt set — details in the methodology. Scoring is explained in How the AI Visibility Score works.
Jump to:
- The leaderboard
- Finding 1: Four of seven tools lost their own home turf
- Finding 2: Gemini cited zero sources. In all 1,506 answers.
- Finding 3: Engines talk about brands 4× more than they link them
- Finding 4: Brands own almost none of their category’s citations
- Per-engine snapshots
- What this means if you market a devtool
- Methodology & limitations
- Sources
The leaderboard
Visibility score on each brand’s own ~220-answer scan (higher = mentioned and cited more, ranked better):
| # | Tool | Score | Mention rate | Citation rate | Won its own scan? |
|---|---|---|---|---|---|
| 1 | GitHub Copilot | 62.8 | 80.9% | 26.8% | ✅ Yes — by 35+ points |
| 2 | Bubble | 48.6 | 65.5% | 23.6% | ✅ Yes |
| 3 | Cursor | 37.5 | 60.7% | 4.1% | ✅ Yes |
| 4 | Lovable | 21.7 | 32.3% | 7.7% | ❌ No — ranked #5, behind Builder.io |
| 5 | Replit | 20.1 | 25.9% | 11.4% | ❌ No — beaten by Figma |
| 6 | Devin | 16.2 | 29.3% | 1.0% | ❌ No — beaten by Cursor |
| 7 | Bolt.new | 11.3 | 26.3% | 0.5% | ❌ No — ranked #7 on its own prompts |
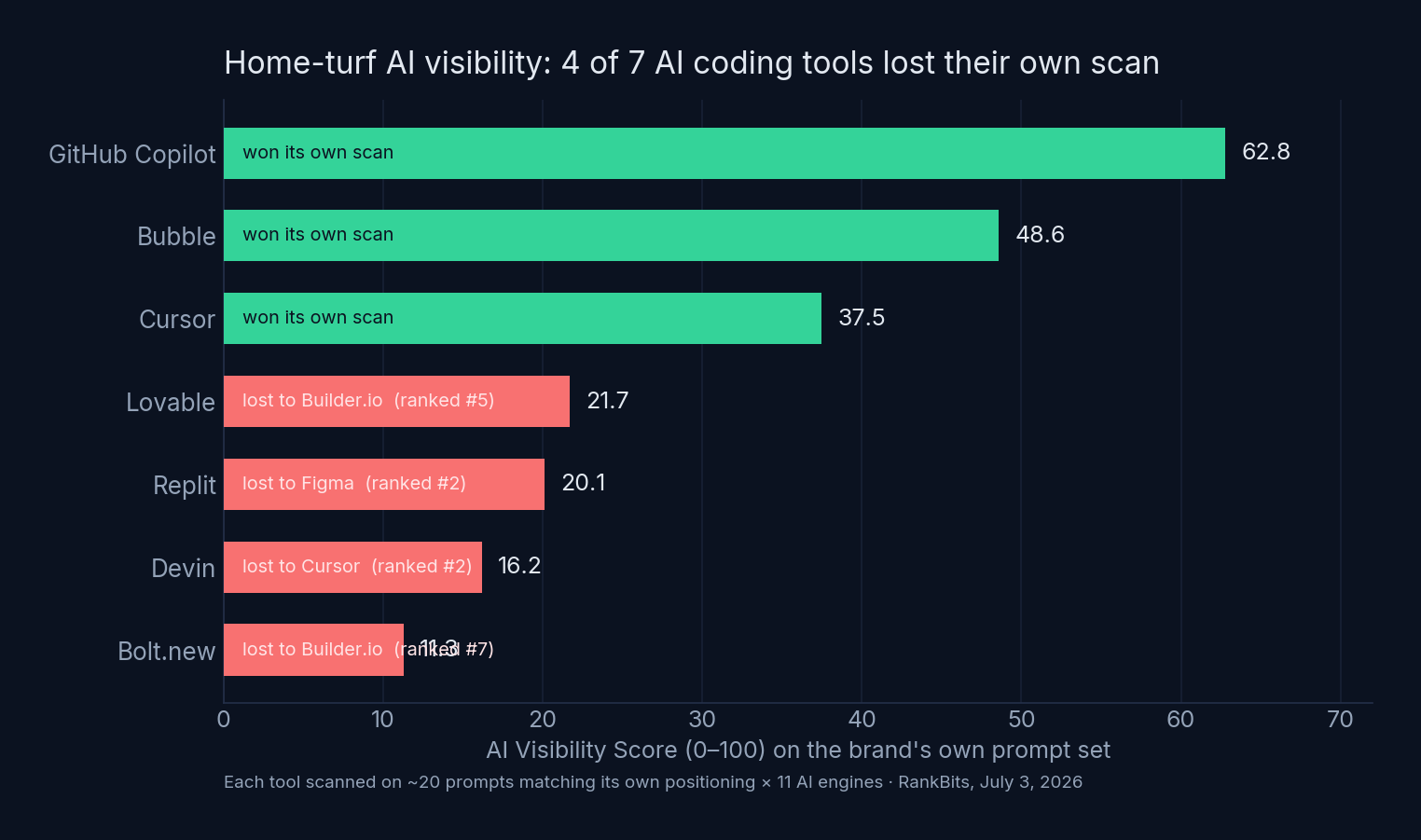
GitHub Copilot isn’t just first — it’s in a different league. Google AI Mode mentioned Copilot in 100% of its prompts, and github.com pulled 228 citations in a single scan. Distribution, a decade of documentation, and Microsoft’s surface area compound in AI answers the same way they did in classic search.
The more interesting story is the bottom half. These are some of the fastest-growing products in software — and when a buyer asks an AI engine the exact question their marketing is built around, the engine often recommends someone else.
Every leaderboard row links to the full public scan — every prompt, every engine answer, every cited URL. Check our work, or run the same scan for your own brand.
Finding 1: Four of seven tools lost their own home turf
This was the result that made us re-check the data. Each scan’s prompts were generated for that brand — the fairest possible arena. The brand still lost in 4 of 7 cases:
| Tool | Its score | Who beat it on its own prompts |
|---|---|---|
| Devin | 15.8 | Cursor — 26.1. Cursor won 11 of Devin's 18 agent-themed prompts |
| Replit | 20.1 | Figma — 22.4 (20.5% citation rate vs Replit's 11.4%) |
| Lovable | 21.7 | Builder.io — 45.7, more than double. Figma Make dominated 5 prompts |
| Bolt.new | 11.3 | Builder.io — 41.4. Bolt ranked 7th, behind Figma, Replit, Lovable, Cursor and Zite |
Two details worth pausing on:
- On Devin’s flagship territory — prompts like “best AI coding agent for managing multiple agents locally and in the cloud” — engines answered Cursor. The category Devin invented is being answered with a competitor’s name.
- On Bolt’s own top prompt, “best AI tool to build a full-stack web app from a text prompt”, Lovable was mentioned by 8 of 11 engines and cited by 3. Bolt: 5 mentions, 0 citations. That is Bolt’s one-sentence pitch, answered with Lovable.
The takeaway: your product’s category ownership in launch videos and social buzz does not transfer to AI answers. Engines assemble answers from the citable web — docs, comparisons, tutorials, forum threads — and if competitors dominate those sources for your use case, they win your prompts.
Finding 2: Gemini cited zero sources. In all 1,506 answers.
Every engine has a personality. Gemini’s is: talks a lot, shows no receipts.
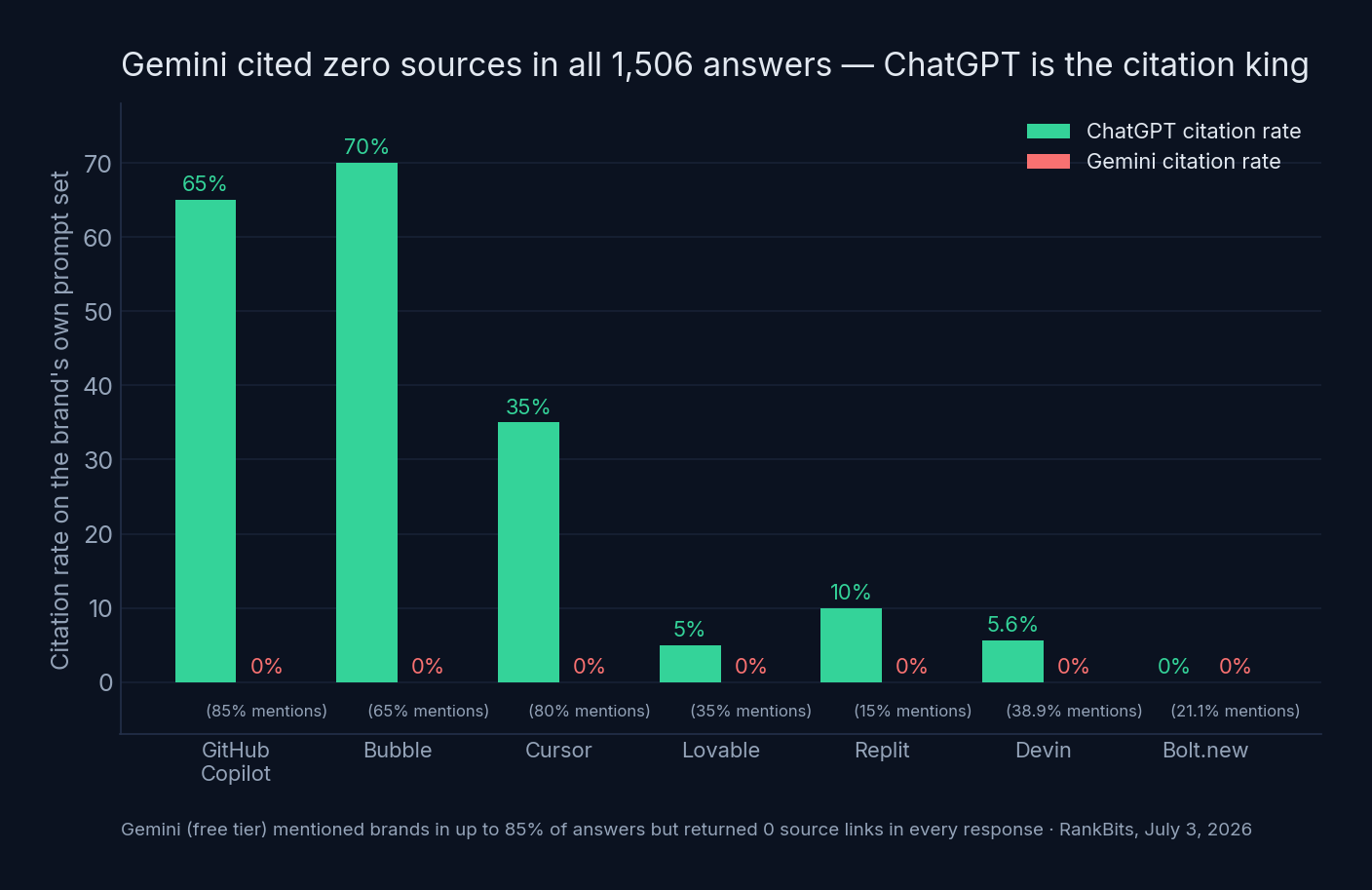
Gemini (free tier) mentioned GitHub Copilot in 85% of answers, Cursor in 80%, Bubble in 65% — and cited a source in 0% of its responses, for every brand, on every prompt. It returned zero source links across the entire study.
ChatGPT is the opposite: the citation king, but a brutal gatekeeper. It cited Bubble in 70% of answers and Copilot in 65% — and mentioned Bolt.new in 0 of 19 prompts. Not low visibility. Zero.
Why it matters: citations are where the click — and the trust — happens. A Gemini mention is brand awareness you can’t audit and the user can’t verify. If your AI strategy is “get linked,” Gemini’s free tier currently has nothing to give you, while ChatGPT decides between making you the answer and pretending you don’t exist.
Finding 3: Engines talk about brands 4× more than they link them
Across all 7 tools, the average mention rate was 45.8% — but the average citation rate was just 10.7%.
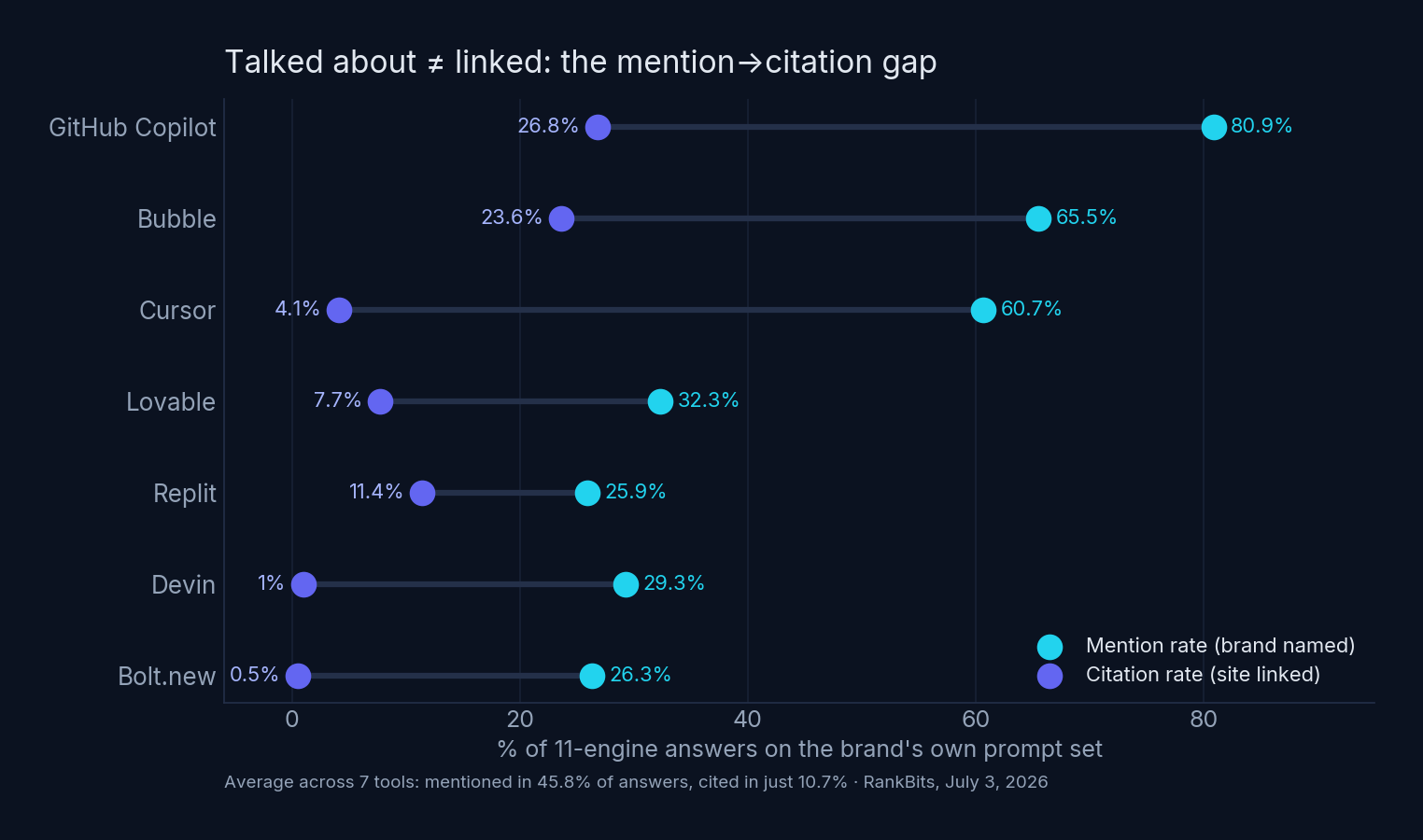
Cursor is the extreme case: named in 60.7% of answers, linked in 4.1%. Engines know Cursor exists — from Reddit threads, YouTube videos, and blog posts — but almost never send the user to cursor.com. Devin: 29.3% mentions, 1.0% citations.
And here’s the inverse anomaly that proves the gap is a strategy, not a law of nature: Augment Code. It appeared as a competitor in three of our scans with a higher citation rate than mention rate — 28.8% citations vs 17.4% mentions on Cursor’s prompts, 26.3% vs 9.1% on Devin’s. Engines rarely gossip about Augment Code, but when they build an answer about enterprise codebases and refactoring, they link augmentcode.com as evidence. Its comparison and use-case pages are doing exactly what citable content is supposed to do.
The takeaway: mentions come from fame; citations come from citable pages — answer-shaped comparisons, docs, and use-case content engines can quote and link. Augment Code shows a small brand can win the second game without winning the first.
Finding 4: Brands own almost none of their category’s citations
When engines answered these buying prompts, whose sites did they actually link? Mostly not the vendors’.
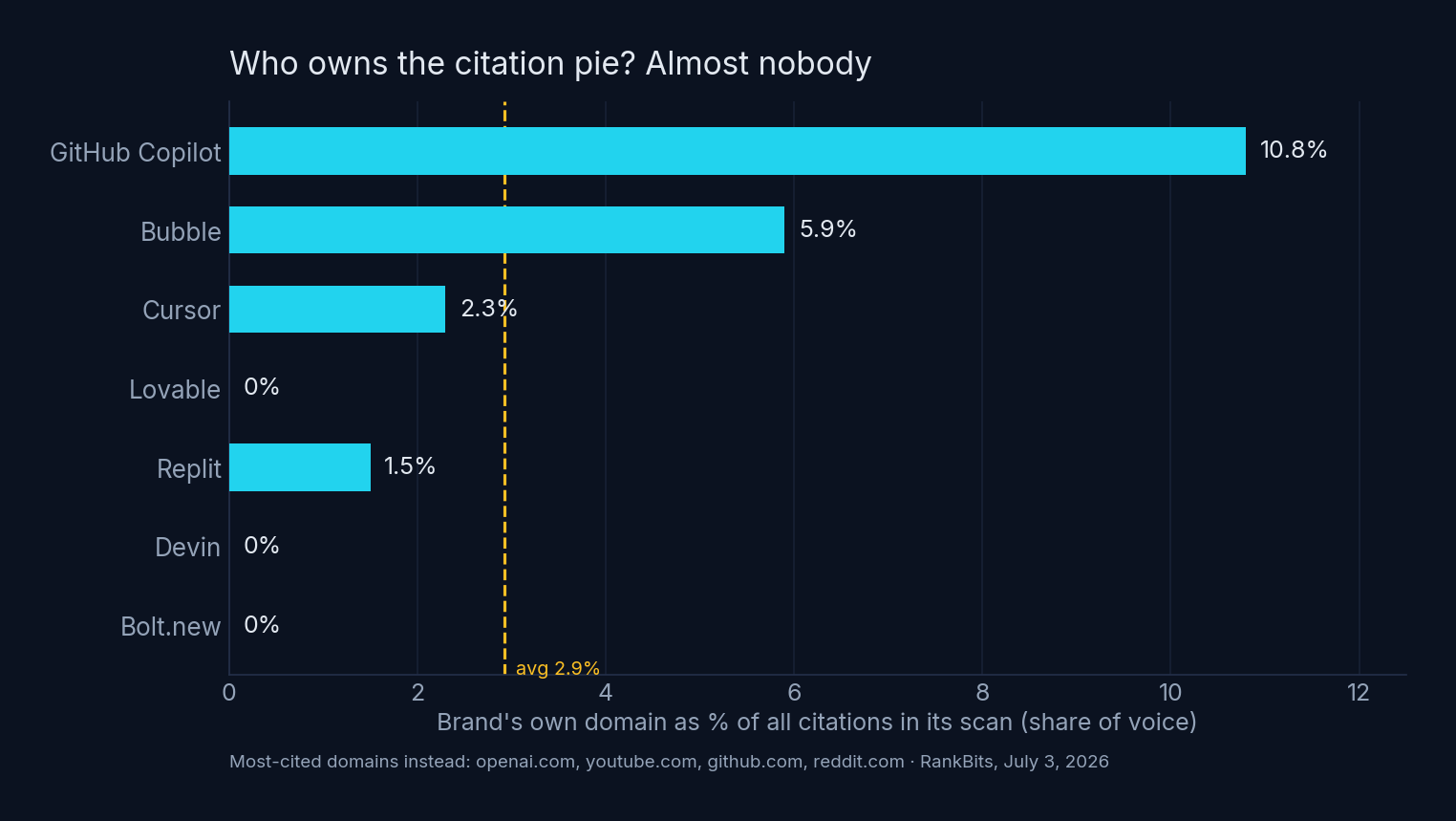
The most-cited domains across the dev-tool scans were openai.com, github.com, youtube.com, and reddit.com — plus medium.com and dev.to. The brands’ own share of the citation pie:
- github.com: 10.8% (the only healthy number, and it’s GitHub)
- bubble.io: 5.9% · cursor.com: 2.3% · replit.com: 1.5%
- lovable.dev, devin.ai, bolt.new: 0.0%
Three venture-backed companies whose websites were never cited once in AI answers about their own category. The conversation about them happens entirely on other people’s domains — which means their positioning, pricing, and comparisons are being paraphrased from third-party sources they don’t control.
One more pattern: the no-code category gets cited ~5× more than the pro-dev category. Bubble’s scan saw a 23.6% citation rate (and even higher for its competitor Adalo at 30.9%), while Cursor sat at 4.1%, Devin at 1.0%, Bolt at 0.5%. Our hypothesis: no-code vendors publish extensive tutorial and template content on their own domains — exactly the content engines cite — while dev-tool knowledge lives on Reddit, YouTube, and personal blogs. If you sell to developers, your citation battlefield is mostly off-domain.
Per-engine snapshots
ChatGPT — the citation king, and the harshest gatekeeper
Highest citation rates in the study (70% Bubble, 65% Copilot) but sharply selective: 0% mentions for Bolt.new, 5.6% for Devin. If ChatGPT knows you, you're the answer; if not, you're invisible. See our companion study on what ChatGPT actually cites.
Gemini — mentions everything, cites nothing
Up to 85% mention rates, 0 sources linked in all 1,506 answers. Awareness channel only — nothing to click, nothing to verify.
Google AI Mode & AI Overview — broad and generous
Consistently top-3 for mentions (AI Mode hit 100% on Copilot's prompts) with moderate citations (up to 45% for Bubble). The closest thing to classic SEO behavior in the study.
Claude — strong mentions, stingy links
75–90% mentions for the leaders but low, occasionally zero, citation rates. Behaves more like Gemini than ChatGPT.
Perplexity — the honest middle
Moderate on both axes; Replit's best engine (40% mentions, 30% citations). Its citation-first UI makes it the easiest engine to audit.
Exa — the semantic sleeper
Ranked #1 or #2 mention engine in most scans (85% Cursor, 95% Copilot). Exa powers retrieval inside other AI products, so visibility here propagates downstream.
Bing Copilot, Bing Search, Google Search, Tavily — the weak tail
Tavily was the weakest engine in nearly every scan (0% for Bolt, 10% for Lovable). Bing Copilot was mid-pack except for Copilot's own scan (95% mentions — make of that what you will). The classic search layers mostly trailed their AI siblings.
What this means if you market a devtool
Do this:
- Track prompts, not just keywords. Bolt.new is invisible on its own best “quick landing page” prompt. You can’t fix a prompt you’ve never measured. Start with your five highest-intent buying questions.
- Build citation-bait pages, not just brand buzz. Augment Code out-cites brands 10× its fame with answer-shaped comparison and use-case pages. Structure yours so an engine can lift a sentence and link it — here’s how to make a page citable.
- Fight the off-domain war. Reddit, YouTube, and dev.to carry most dev-tool citations. Authentic threads, tutorials, and creator coverage move AI answers more than another homepage rewrite. Work through the GEO checklist.
- Audit per engine. Your ChatGPT problem and your Gemini problem are different problems. One needs citable sources; the other can only ever mention you.
- Watch your competitors’ prompts, not just your own. Cursor didn’t just defend its turf — it won Devin’s. The upside of this dynamic is available to you too.
Skip this: chasing Gemini citations (there are none to chase), assuming launch-week virality equals AI visibility (Bolt and Lovable disprove it), and treating AI visibility as one number — the engine-level spread is the signal.
Methodology & limitations
We believe research is only useful if you can attack it, so: every scan is public, and here’s everything that would let you.
- Setup: 7 brands scanned July 3, 2026 with RankBits. ~20 auto-generated buying-intent prompts per brand (18–20 after dedup) × 11 engines = 219, 198, 220, 220, 209, 220, and 220 recorded answers respectively — 1,506 total.
- Engines: ChatGPT, Gemini, Claude, Perplexity, Google AI Mode, Google AI Overview, Google Search, Bing Search, Bing Copilot, Tavily, Exa (free/default tiers).
- Metrics: a mention = the brand named in the answer text; a citation = the brand’s domain linked as a source. Scores blend mention rate, citation rate, and citation rank — full definition in the AI Visibility Score explainer.
- Limitation — prompts are per-brand, and not equally competitive. Each tool was scored on its own auto-generated prompt set, not an identical shared list. Some prompts are broad, high-intent, high-competition queries (“best AI coding agent for startups”); others are narrower or more niche to that brand’s positioning. That means scores are best read as “how well each tool holds its own turf,” not a strict apples-to-apples ranking across brands — a tool with easier, less-contested prompts has a structural advantage over one whose prompt set is more competitive. This is also why the home-turf losses in Finding 1 are notable: the arena was tilted in each brand’s favor, prompt difficulty included.
- Limitation — no independent search-volume data. Prompt-level search-volume estimates shown inside RankBits scans are AI-generated approximations, not verified data from a keyword tool — we deliberately excluded them from this article’s stats and used them only as rough color, dropped anywhere we weren’t confident in the number.
- Limitation — single run. AI answers are non-deterministic; a rerun will shift individual percentages (directionally the patterns held across scans, e.g., Gemini’s 0% citations in all 7). This is a snapshot, not a permanent ranking.
- Limitation — free tiers. Paid tiers (ChatGPT Pro, Gemini Pro, Claude Pro) may answer differently; they’re in scope for the next run.
- We had an eighth scan (Softr) that wasn’t public at publication time; Softr still appears as a competitor inside the Bubble and Lovable scans.
We’ll re-run this monthly and track who gains and loses ground. If you want your tool included in the next run, tell us.
Sources
- GitHub Copilot scan · 2. Bubble scan · 3. Cursor scan · 4. Lovable scan · 5. Replit scan · 6. Devin scan · 7. Bolt.new scan — each includes every prompt, every engine answer, and every cited URL.
Want to know what AI engines say when buyers ask about your category? Run a free RankBits scan →


